Mathieu Tozer's Dev Blog
Cocoa, the development of Words, and other software projects (including those dang assessment tasks).
Language Detection
Published Saturday, January 14, 2006 by Mathieu.
I wrote something on language detection too. Haven't proof read. Too tired.
--
How might Words detect which language it is looking at?
The most simple strategy might be to search dictionaries of the entered word, and the one that returns a hit is the language being used. But when there are similar words that appear in different languages, there needs to be a better strategy, so that the computer doesn't get confused.
Actually, this could be A FEATURE. The option could be that if the language is found in the dictionary of the 'active' language, then it is added, and no further searching is done. But If it is first found in other languages... actually no, the option should be that all dictionaries are searched, and added to, or all dictionaries are searched, and only the active language is added to. This should work for most people, since at any one time a user would be learning only a few languages, and so their words to remember list shouldn't grow too quickly.
So in conclusion, a word is entered to words, it is either searched for in all dictionaries, and added to all languages it returns results for, or it only searches the 'active' language. Which means that if the user switches languages, they have to let words know somehow.
If the word is not found in the active language, THEN words searches the other dictionaries of languages the user is learning, and if it finds a hit, adds it. If ti finds hits in multiple language dictionaries, then it must then ask the user which language. OR it could make intelligent languages, like if there is any hiragana surrounding the word, or the encoding. The encoding of the selection, if it makes it though the copy and paste / services insertion method, might be very useful in unambiguously finding which language is being inserted. A simple reference lookup table would show which language we're talking about!
After all we're talking about rich text here, not just plain text, which means that there's all kind of delicious metadata waiting to be used.
This language detection thing could be extended to be incorporated by browsers for encoding detection, to remove that irritating view->encoding->Japanese. 1. 2. 3 aah there we go I can actually read that kind of thing. If I can figure out a way to make software workout whether a language is displaying properly then that would be good.
--
I love it, I have to record on the sheet all the events that happen in the solarium in a day. Right down to the beds flicking on automatically occasionally
--
How might Words detect which language it is looking at?
The most simple strategy might be to search dictionaries of the entered word, and the one that returns a hit is the language being used. But when there are similar words that appear in different languages, there needs to be a better strategy, so that the computer doesn't get confused.
Actually, this could be A FEATURE. The option could be that if the language is found in the dictionary of the 'active' language, then it is added, and no further searching is done. But If it is first found in other languages... actually no, the option should be that all dictionaries are searched, and added to, or all dictionaries are searched, and only the active language is added to. This should work for most people, since at any one time a user would be learning only a few languages, and so their words to remember list shouldn't grow too quickly.
So in conclusion, a word is entered to words, it is either searched for in all dictionaries, and added to all languages it returns results for, or it only searches the 'active' language. Which means that if the user switches languages, they have to let words know somehow.
If the word is not found in the active language, THEN words searches the other dictionaries of languages the user is learning, and if it finds a hit, adds it. If ti finds hits in multiple language dictionaries, then it must then ask the user which language. OR it could make intelligent languages, like if there is any hiragana surrounding the word, or the encoding. The encoding of the selection, if it makes it though the copy and paste / services insertion method, might be very useful in unambiguously finding which language is being inserted. A simple reference lookup table would show which language we're talking about!
After all we're talking about rich text here, not just plain text, which means that there's all kind of delicious metadata waiting to be used.
This language detection thing could be extended to be incorporated by browsers for encoding detection, to remove that irritating view->encoding->Japanese. 1. 2. 3 aah there we go I can actually read that kind of thing. If I can figure out a way to make software workout whether a language is displaying properly then that would be good.
--
I love it, I have to record on the sheet all the events that happen in the solarium in a day. Right down to the beds flicking on automatically occasionally
Posting from MarsEdit
Published by Mathieu.
Testing sending from MarsEdit. Is there a WYSIWYG editor too?
Spaces
I guess I could get used to this. I'll give it a try. Will still probably do most of my typing on my Newton eMate when I'm out and about and in Text Editor when I'm home, and save this program for formatting.
Citing is fun.
Spaces
Block Quotes!
I guess I could get used to this. I'll give it a try. Will still probably do most of my typing on my Newton eMate when I'm out and about and in Text Editor when I'm home, and save this program for formatting.
Citing is fun.
Parsing Issues
Published Friday, January 13, 2006 by Mathieu.
I wrote all this today while at work at MegaSun. I tapped it out on my newton, the screen wasn't so readable, and I haven't proofed through it yet. So it might be all crap. So there you go!
--
The dictionary look-up utility must be versatile enough to lookup words in any dictionary, in any language. The dictionary choosing utility must be able to handle the lookup utility, or rather must interface with it neatly. so that it can handle the steady stream of words coming in, and (perhaps) advise the lookup utility which language [encoding] the word is so that it searches the right dictionary.
Complexity generally increases towards the dictionary lookup facility, then decreases afterwards as the word gets through to the actual application and is inserted in the appropriate list under its language.
What if the development of some part of this could be done in C++, and factored out into one of my uni assignments, so that I can minimise the amount of work being done. I don't want to have to work on some dumb project unrelated to my Words project while trying to get that done as well.
It is difficult to asses the actual amount of work that each component amounts to. Various unseen obstacles will most likely stand in the way, unforeseen things that didn't rear their ugly heads in the specs.
If I can encapsulate the various parsing modules, develop them, and put them all together into a working unit, where the OUTPUT of the last module interfaces with Words, then great. This removes some of the complexity from the main app (but is used by it).
So these are the steps.
1. Initial formatting (make plain text etc, correct encoding)
2. Separation of texts into words (with their context saved)
3. Checking for prior existence in user dic (warning:: synonym killer)
4. Determining Encoding, therefore language, attaching to word (if not done in first step)
5. Passing word to lookup utility which
5.1 Checks active lang dicts, then other lang dicts for a hit. Word is output with dictionary data attached.
6. Word is input into the application proper and other metadata (date, knowledge level, list and language word belongs to) is added.
7. Application adds new words to the user dictionary for that language. (Could the same lookup utility be used for looking up user dictionaries?) = Less code! And less code is always better code.
Then we will have our goal. Lists of words that you have seen, and haven't seen, displayed in user defined smart lists, with their dictionary attributes showing, and all the user had to do was drag in a block of text.
The above is what would happen in a 'perfect' world. There are some snags along the way.
Like the synonyms getting chucked in the bin by showing that they've been seen before. This could be overcome by dictionaries that flag words that are synonyms.
There's also the issue of some words having multiple meanings, so the dictionary searches and chucks words out the other end with more than one translation attached to them. The best solution I have for this so far is to have a clarifier ask the user which word they mean. In practice, I hope, users won't have THAT many new words to learn, so that they won't be swamped with long hours of classifying words into what they mean. That would be the direct opposite of what this program is designed to do. But if it were something like 10 words or so in a bunch that needed some clarification (synonyms etc.) then that could work.
The option for words that go un-clarified (say the user never bothers to do it) is to leave all translations attached to the word.
Think: What would users (I almost said I) be doing manually?
When they encounter a word in a dictionary, and see many variations, do they only choose the one and chuck out the rest for a later time, or do they try to absorb them all so that in the future when they encounter it in the real world they have a better chance of understanding it in context. Something to find out would be whether dictionaries give a 'most common' usage of a word, so that can be displayed most prominently to minimise clutter, and then with further disclosure a word can reveal its other, similar meanings.
THUS Adhering to simplicity, reveal complexity when it it needed, which is some of the time. Otherwise, show only the basics, so that (as per the google homepage) what you want to get done most of the time is shown most of the time, without clutter.
Closed swiss army knife.
I think this strategy might work. Expand a row containing a word to reveal more detailed information about it.
The other is the issue of determining which language a word (or set of words) belongs to. Generally an input text is all in a single language. No can that, word lists given by teachers sometimes have the translations put in them already. (Note: users should be able to change the autolookup translation to anything their teacher tells them it is, we don't want students loosing marks because they called something sematically the same but not what the teacher ordered) And some texts or webpages might contain various languages. Thefore language (if it is determinable at all) should be determined on a word by word basis. I hope the added processing doesn't kill the speed of proceedings too harshly!
There is also the issue of keeping the textual context in the word. Does the parser go back once the word has made it through the other texts and grab the sentence the word has just come from by searching for the first instance of it? Or does the word object carry it though the whole system from word go? The latter seems to be complex, and makes the system carry a lot more extra baggage than is really necessary. The former method means that the text will need to be kept as long enough is needed to get all the words that made it through aligned with their context text and then put away neatly.
There is also a need to the user dictionary to record how many 'hits' a word gets, so that the importance or regularity that a word has can be monitored and reflected in the application. This should be a simple matter of incrementing an integer each time a word is queried.
So there I have several modules that all fall under the header of 'parser', and is essentially the crux of the main functionality of the program (other functions include flashcarding, iPod export and record, networked features etc.)
Therefore this is the section that I need to start on first.
I don't need to decide yet what language I'm going to be implementing in, that is a minor consideration cmpared to the overall architecture. And I needn't worry about what will happen after the neatly packaged 'new word' object is passed to the application proper.
Let's just believe that computer science at Monash University doesn't do much for your programming confidence if you're not very good at writing command line disk drivers and semaphore handlers in procedural C. No matter how good a designer or OO programmer you are you're not going to get very good marks.Your design and algorithms should just slip into code when they are ready to. Don't force it, just keep on designing.
So to design the first phase of the parser: Formatter.
\\excerpt\
Ok, back to the formatter.
Input: Text as plain, rtf, or HTML etc, from 1 to x number of words long.
Only works if separate words are separated by whitespace. Therefore Asian Scripts as they normally are, are not supported at this stage unless they are seaparated by a space, for example. Will of course work fine for single words.
Output: Plain text object to be parsed in encoding information intact.
Inside, the text is made plain text. All HTML
Make everything lower case. Put the text into a special object and pass it on as the output.
The second step for the journey is that of a small handler that dishes out words consecutively.
It could actually encase the dictionary look up utility(step 3) in the sense that it calls it to look up a word on every iteration, passing a single word to it. It takes as input a formatted text object and outputs individual words as a string with their encoding details attached (if this is available to be used to identify languages).
The third step is the lookup utility.
It takes as input an individual word, and it has access to the various user and non user language dictionaries in the system.
At this step it is only concerned with the user dictionaries. When a simple word object (a wrappered string with encoding info attached?) is sent to it, it always only check the user dictioanry (although this might upset the general nature of the utility, the only need I see for it at this stage is for the parsing). We'll roll with it.
When called at this stage and passed only a single word, the dictionary looks in the appropriate language's user dictionary and sees if an entry already exists. If there is an identical entry, and the entry does not have a synonym, then the word is chucked (ie, already seen the word before) The entry does get updated with a new 'times seen' increment. If there is no prior entry, the word object is output with 'new' flagged. So The lookup utility OUTPUTS a new word object of class word, at this stage with the fact that it has not been seen before flagged.
The fourth step for a word is to be INPUT again into the Lookup Utility again, but this time, the lookup utility searches language dictionaries (see note about language selection) for instances of the word. The procedures for this have been documented elsewhere, but the end result is that thelookup utility then OUTPUTS the word object with all the search results that it obtained in the lookup entered into the object.
(Now I am thinking that the two lookup utilities described would be better as two separate code bases as the second one has to do considerably more. Although there are some similarities... perhaps closer examination of actually what data the entities will manipulate will help make this distiction clearer and help in deciding).
The next step involves the contextualiser, which takes as INPUT the original text (I mean the very original, not the formatted one) and it is scanned for each new word. The sentence it occurs in (from last full stop to the proceeding full stop perhaps) is coped into the object and OUTPUT to the next stage.
The next step is to use the insert function on the appropriate user dictionaries to INSERT all the new word objects into the user dictionaries.
Now we have a pool of objects (although this all really happens ina streamlined manner, without objects really waiting anywhere) to be inserted into the application sphere, which is not discussed here in detail, but I will say that thet are set and ready to have other application (ie non word specfic) metadata associated to them such as the time and date, their initial knowledge level set (nothing) etc etc, and also to which list they belong to.
The next steps involve researching which dictionaries I am going to be interfacing with, and what kind of results I can expect to have returned from them when given search criteria. #What kind of serch criteria do they require?
Then it might be a good idea to see what frameworks there are already available that I can use, so that I don't have to invent them myself. Like the input of various files and their conversion to plain text.
{kind=link}
Clarifying Ambiguous Dictionary Search Results in Words
Published Wednesday, January 11, 2006 by Mathieu.
While Working last week, I addressed some issues with my presently stalled Words project. Issues that I have thought of but have wondered how I might overcome them but not had much of an idea. Seems like they're not going to go away by themselves so here it is.
In the perfect world, a dictionary would know exactly which translation of a word you want. But sometimes, nay, most of the time, you get back a result something like this:
translation
トランスレーション
translation
翻訳書 [ほんやくしょ]
(n) translation
訳出 [やくしゅつ]
(n) translation
訳書 [やくしょ]
(n) translation
訳述 [やくじゅつ]
So, in the perfect world, Words would automatically choose the one we want, and slot it in. There are times when the results are even longer and more ambiguous. Some words blissfully return just the one result, but language just isn't like that (a good thing though).
What about a simple window / sheet which has the sole purpose of clarifying which translation you [mainly] want in your lists. So the original word is displayed, with the dictionary search results beside it, and you simply click once on the one you think is right, and move on. The word entry is changed accordingly, and the alternate translations are pushed back into an alternate translations field.
Fussy, messy, and not a very good user experience. But if I want automatic lookup of words...
Here's the sketches I drew:
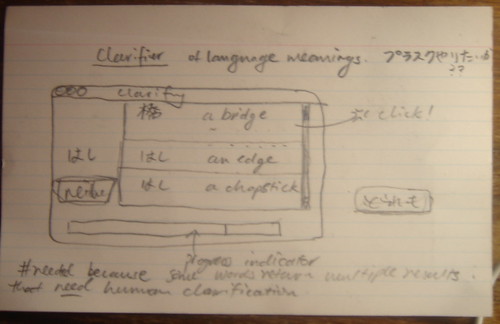

In the perfect world, a dictionary would know exactly which translation of a word you want. But sometimes, nay, most of the time, you get back a result something like this:
translation
トランスレーション
translation
翻訳書 [ほんやくしょ]
(n) translation
訳出 [やくしゅつ]
(n) translation
訳書 [やくしょ]
(n) translation
訳述 [やくじゅつ]
So, in the perfect world, Words would automatically choose the one we want, and slot it in. There are times when the results are even longer and more ambiguous. Some words blissfully return just the one result, but language just isn't like that (a good thing though).
What about a simple window / sheet which has the sole purpose of clarifying which translation you [mainly] want in your lists. So the original word is displayed, with the dictionary search results beside it, and you simply click once on the one you think is right, and move on. The word entry is changed accordingly, and the alternate translations are pushed back into an alternate translations field.
Fussy, messy, and not a very good user experience. But if I want automatic lookup of words...
Here's the sketches I drew:
Mucking Around with CSS
Published by Mathieu.
Since I borrowed my friend's graphics tablet, and I've had a long
dormant version of Photoshop CS installed, I put the two together and
have had fun work shopping some stuff. What you see around you (at
time of publishing) is the result - yet still a work in progress.
Comic Life (Japanese version) Documentation proofs are slowly coming
in, and this is how I have been spending some of my spare time.
Subjects for 2006 are enrolled, even allocated. I'm only looking at
10 on campus contact hours, but with the evil way they plan things at
Universities that probably means that I've got tonnes of work to
finish at home.
dormant version of Photoshop CS installed, I put the two together and
have had fun work shopping some stuff. What you see around you (at
time of publishing) is the result - yet still a work in progress.
Comic Life (Japanese version) Documentation proofs are slowly coming
in, and this is how I have been spending some of my spare time.
Subjects for 2006 are enrolled, even allocated. I'm only looking at
10 on campus contact hours, but with the evil way they plan things at
Universities that probably means that I've got tonnes of work to
finish at home.
About me
- I'm Mathieu
- From Taipei, Taipei, Taiwan
- Vcard English 日 漢
- My profile
Last posts
- This Blog is Closed
- 2007-08-14 19:09:36.041 XXX[2591:10b] {{134.808, 6...
- ZINGLES!!! ZINGLE ZINGLE ZINGLE!!! IT WORKED!!!!
- About to code something into my project which coul...
- Thinking it would have been better to not have bee...
- It's funny how I tend to hold my breath while usin...
- WWDC2006 Student Sunday notes from the Pixar Guy
- Smart Lists Revisited
- Grokking NSBezierPaths
Braawse
- 2005-08-07
- 2005-08-21
- 2005-09-18
- 2005-09-25
- 2005-10-02
- 2005-10-09
- 2005-10-16
- 2005-10-23
- 2005-10-30
- 2005-11-06
- 2005-11-13
- 2005-11-20
- 2005-11-27
- 2005-12-04
- 2005-12-11
- 2005-12-25
- 2006-01-01
- 2006-01-08
- 2006-01-15
- 2006-01-29
- 2006-02-05
- 2006-02-12
- 2006-02-19
- 2006-02-26
- 2006-03-05
- 2006-03-12
- 2006-03-26
- 2006-04-02
- 2006-04-09
- 2006-04-16
- 2006-04-23
- 2006-04-30
- 2006-05-07
- 2006-05-14
- 2006-05-21
- 2006-05-28
- 2006-06-04
- 2006-06-11
- 2006-06-18
- 2006-06-25
- 2006-07-02
- 2006-07-09
- 2006-07-16
- 2006-07-23
- 2006-07-30
- 2006-08-06
- 2006-08-13
- 2006-08-20
- 2006-08-27
- 2006-09-03
- 2006-09-10
- 2006-09-17
- 2006-09-24
- 2006-10-01
- 2006-10-08
- 2006-10-15
- 2006-11-05
- 2007-01-14
- 2007-04-15
- 2007-04-22
- 2007-05-06
- 2007-08-05
- 2007-08-12
- 2008-02-10